






超小型AIスーパーコンピューターASUS Ascent GX10
NVIDIA DGX™ Spark ベース
ASUS Ascent GX10は、NVIDIA GB10 Grace Blackwell Superchip と、AIの開発や動作に必要なソフトウェアがまとまった「AIソフトウェアスタック」を搭載しています。
これにより、AIの作成から実際の運用までを一貫して支援する「フルスタックソリューション」として提供されます。高い計算能力と効率的な作業の流れを実現し、コンパクトな設計で、システムの導入もスムーズに行え、優れたAI性能を求める開発者にぴったりです。
さらに、最新のAIツールと高速ネットワーク技術のNVIDIA® ConnectX-7にも対応しており、AIの可能性を広げながら、独自の開発を強力にサポートします。
ご要望に合わせてご提案







-

NVIDIA® GB10 Grace Blackwell Superchip 搭載
-
128GB LPDDR5x コヒーレント統合システムメモリ
-
1 ペタフロップス(PFLOPS)
のAIパフォーマンス
-

-
NVIDIA®
NVLink™-C2CPCIe Gen 5の5倍の帯域幅で、CPU+GPU を統合するメモリモデルを実現
-
NVIDIA® DGX OS(Ubuntu Linuxベース)
-
NVIDIA® ConnectX®-7
2台のGX10システムを連携し、さらに大規模なモデルの処理にも対応可能
-
最適化された
冷却設計 -
NVIDIA AIソフトウェアスタック
-
AI 開発環境
NVIDIA NIM™とBlueprintsを活用し、PyTorchやJupyter、OllamaといったツールでAIの試作(プロトタイピング)や推論をスムーズに行えます。
デザイン
デスク上で実現する本格的なAIパフォーマンス
最先端のNVIDIA® GB10 Grace Blackwell Superchip(NVIDIA DGX Spark採用)を搭載した画期的なASUS Ascent GX10 AIスーパーコンピューターは、ペタフロップ(PFLOPS)級のAIコンピューティングパワーを開発者、AI研究者、データサイエンティストに提供します。この革新的なデバイスは、卓越した性能と先進機能でローカル環境での AI開発を力強くサポートします。
コンパクト、高性能、
拡張性
コンパクトサイズ:150mm x 150mm x 51mm

比類なきAIパフォーマンス
FP4演算による
最大1ペタフロップ(PFLOPS)のAI性能
大規模なAIワークロードも強力に処理可能
128GBコヒーレント統合システムメモリ
十分なメモリ容量で、
モデル開発・実験・推論を強力にサポート
-
FP4演算による最大
1 PFLOP
のAIパフォーマンス
-
128GB
コヒーレント統合
システムメモリ
最先端アーキテクチャ
NVIDIA GB10 Grace Blackwell Superchip:
ASUS Ascent GX10の中核をなすこの先進チップは、第5世代TensorコアとFP4に対応した高性能Blackwell GPUを搭載しています。
高性能20コアArm CPU:
データの準備や管理を効率化し、AIモデルの調整やリアルタイムでの推論処理を速く行えます。
NVLink™-C2Cテクノロジー:
PCIe 5.0の5倍の帯域幅でCPU+GPUを統合するメモリモデルを実現します。


大規模パラメータ生成AIモデルに対応
最大2000億パラメータのAIモデルをサポート
最新のAI推論モデルをデスクトップ上で、製品・システムの検証(プロトタイピング)、微調整(ファインチューニング)、既存AIモデルの特定用途向け最適化が可能
NVIDIA® ConnectX®-7ネットワーク技術を統合
2台のASUS Ascent GX10を連携させることで、Llama 3.1(4050億パラメータ)などさらに大規模なモデルにも対応
AIネットワーキング
次世代接続性:NVIDIA® ConnectX-7対応
ASUS Ascent GX10は、NVIDIA® ConnectX-7を搭載し、超高速ネットワークでAIの分散処理におけるデータ転送をスムーズかつ低遅延で実現します。

超高速AIデータスループット
最大400Gb/sの帯域幅により、ノード間で極めて高速なデータ転送を実現。大規模な分散AIワークロードに最適です。

安全でインテリジェントなネットワーク
TLS、IPsec、MACsecのハードウェアアクセラレーションを搭載し、CPUに負担をかけずに暗号化データ通信を行い、高いセキュリティを実現します。

高精度なパフォーマンス
IEEE 1588v2 PTPに対応しており、AIやエッジコンピューティングなど、時間のズレが許されないアプリケーションでもマイクロ秒単位の正確な時刻同期が可能です。
AIエクスペリエンス
スムーズな開発を実現する統合AIソフトウェアスタック

即時開発可能なAI環境をプリインストール
NVIDIA DGX OS(Ubuntuベース)- 最適化されたAI環境ですぐに利用可能。
NVIDIA AIソフトウェアスタック-迅速な導入のためのフレームワーク、SDK、ツールをプリインストール。

最適化されたAIツール&AIフレームワーク
CUDA、PyTorch、TensorFlow、Jupyter - AIモデル開発と推論のために最適化。
NVIDIA TensorRT - 高性能AI推論エンジン。
NVIDIA NIMs & Blueprints - 事前構築済みAIワークフロー&マイクロサービス。

業界最先端AIモデル対応
DeepSeek R1 - 最大700億パラメータに最適化されたAI推論対応。
Llama 3.1 - デュアルGX10で最大4050億パラメータの生成AIに対応。
Meta、Googleモデル - 業界最先端のAIフレームワークとの幅広い互換性。

サーマルデザイン
究極の冷却効率を追求した
精密設計
ASUS Ascent GX10 は、AI が要求する最も負荷の高いワークロードにも対応します。
高度なデュアルファン設計と7段階制御により、最適化されたエアフローを実現。
従来の同等コンパクトシステムと比べて1.6倍の効率的な冷却カバー率を誇り、GX10は常にシステム温度を低く維持しながら、最高水準のパフォーマンスを持続的に発揮します。
スケーラブル
最大効率を追求した設計

最適化冷却設計により、重いAIワークロードでもパフォーマンスを持続。
コンパクトなフォームファクターで、小型筐体でも高密度なAIコンピューティングを実現。
コネクティビティ
I/Oポート

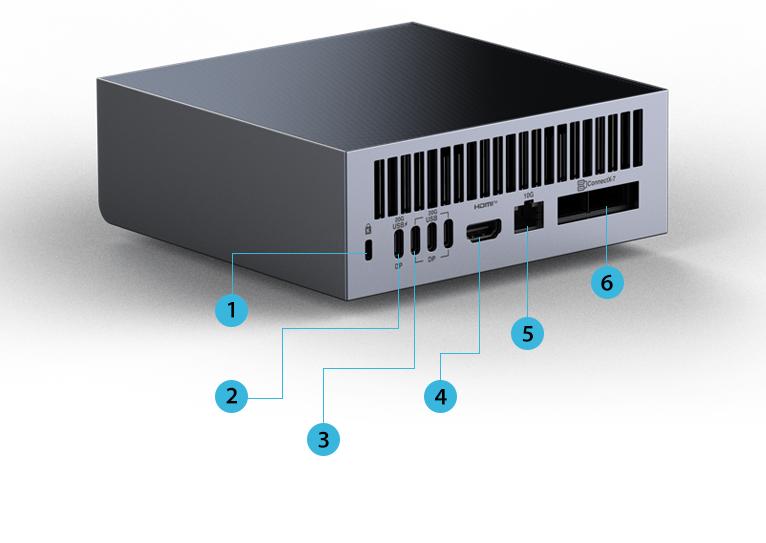
1ケンジントン ロックスロット
21 x USB 3.2 Gen 2x2 Type-C 20Gbps、
代替モード(DisplayPort 2.1)、PD入力付き(180W EPR PD3.1仕様)
33 x USB 3.2 Gen 2x2 Type-C、20Gbps、
代替モード(DisplayPort 2.1)
4HDMI 2.1b ポート
510 GbE LAN対応
61 x ConnectX CX-7 200Gbps (2xQSFP)
アプリケーション
ローカル開発から大規模展開まで対応。

クラウドへのスムーズな移行
NVIDIA AIプラットフォームのソフトウェアを使い、デスクトップ環境からDGX Cloudや高速クラウド、データセンターへ簡単にモデルを移行できます。コードの変更もほとんど必要ありません。
コスト効率の高い実験プラットフォーム
本番用モデルのトレーニングやデプロイに適したクラスター環境を提供。計算リソースを有効に使い、効率的に作業できます。

プロトタイピング

ファインチューニング(Fine-tuning)・推論

データサイエンス
最新情報を受け取る
ASUS Ascent GX10 は2025年10月15日より法人向けに販売開始しました。
本製品に関する問い合わせやご購入に関する詳細は、下記専用窓口よりご確認ください。
今すぐお問い合わせ仕様および製品画像は予告なく変更されることがあります。


